여기서 알아볼 것은 메모리 모델. 가상 머신 메모리에 저장되는 것들이 만들어지는 시기, 저장되는 상세 구조, 접근 방식 같은 것들. 상세 내용에 대해 알아보기 위해 특정 가상 머신과 특정 메모리 영역으로 범위 좁혀 시작 ㄱ. 이왕이면 실용적인 학습이 되도록 보편적인 가상 머신인 핫스팟과 가상 보편적인 메모리 영역인 자바 힙을 예로 들어 설명.
주제는 핫스팟이 관리하는 자바 힙에서의 객체 생성(할당), 레이아웃, 접근 방법 등 전체 과정의 상세 내용
객체 생성
- 자바는 OOP 언어. 자바 프로그램 동작 동안 언제든 수시로 객체 생성됨
- 언어 수준에서는 new 키워드 쓰면 끝나지만, 가상 머신 수준에서는 과연 어떤 과정을 거쳐 객체(배열과 Class 객체가 아닌 일반적 자바 객체가 생성 될까?
- 자바 가상 머신이 new 명령에 해당하는 바이트코드 만나면, 이 명령의 매개 변수가 상수 풀 안의 클래스를 가리키는 심벌 참조인지 확인
- 그런 다음 이 심벌 참조가 뜻하는 클래스가 로딩, 해석(resolve), 초기화(initialize)되었는지 확인
- 준비되지 않은 클래스라면 로딩부터 해야함.
- 클래스 로딩과정은 7장에서 자세히
- 로딩이 완료된 클래스라면 새 객체를 담을 메모리 할당
- 객체에 필요한 메모리 크기는 클래스를 로딩하고 나면 완벽히 알 수 있음(계산 방법은 2.3.2 참고)
- 객체용 메모리 공간 할당은 자바 힙에서 특정 크기의 메모리 블록을 잘라 주는 일이라 할 수 있음
- 자바 힙이 완벽히 규칙적이라 갖정하면 사용 중인 메모리는 모두 한쪽에, 여유 메모리는 반대쪽에 위치하며, 포인터가 두 영역의 경계인 가운데 지점을 가리키게 될 것. 이 상태에서 메모리 할당하면 포인터를 여유 공간쪽으로, 정확히 객체 크기만큼 이동시키게 됨
- 이런 할당 방식을 포인터 밀치기(bump the pointer)
- 하지만, 자바 힙은 규치적이지 않음!
- 사용 중 메모리와 여유 메모리 뒤섞여 있어 포인터 밀쳐 내기 간단 X
- 그 대신 가상 머신은 가용 메모리 블록들을 목록으로 따로 관리하며, 객체 인스턴스를 담기에 충분한 공간 찾아 할당 후 목록을 갱신
- 이 할당 방식을 여유 목록(free list) 라 함
- 어떤 방식 쓸지는 자바 힙이 규칙적이냐 아니냐에 따라 다르고, 자바 힙이 규칙적이냐는 사용하는 가비지 컬렉터가 컴팩트(compact: 모으기)를 할 수 있냐에 달림
- 따라서, 시리얼과 파뉴(ParNew)처럼 모으기가 가능한 컬렉터를 사용하는 시스템은 단순하고 효율적인 포인터 밀치기 방식의 할당 알고리즘 채택하고, 이론상의 CMS처럼 스윕(sweep: 쓸기) 알고리즘을 적용한 컬렉터 쓰는 시스템은 더 복잡한 여유 목록 방식 채택 할 것
- 가용 공간을 어떻게 나눌(할당)지 외에도 고민할게 또 있음. 멀티스레딩 환경에서 여유 메모리의 시작 포인터 위치를 수정하는 단순한 일도 스레드 안전않기에 여러 스레드가 동시에 객체를 생성하려할때 문제 발생 가능성 존재
- 예컨데 한 스레드가 요청한 객체 A를 위해 메모리 할당 과정에서, 포인터 값 수정전에 다른 스레드가 객체 B용 메모리를 요청할 수 있음
- 해법은 2가지
- 첫째는, 메모리 할당을 동기화 하는 방법
- 실제로 비교 및 교환(CAS)과 실패 시 재시도 방식의 가상 머신은 갱신을 원자적으로 수행
- 둘째는, 스레드마다 다른 메모리 공간을 할당하는 방법
- 스레드 각각이 자바 힙 내에 작은 크기의 전용 메모리를 미리 할당 받아 놓는 것.
- 이런 메모리를 스레드 로컬 할당 버퍼(TLAB)라 함
- 각 스레드는 로컬 버퍼에서 메모리를 할당 받다가 버퍼 부족해지면 그때 동기화해 새로운 버퍼 할당 받는 방식으로
- 가상 머신이 스레더 로컬 할당 버퍼 사용할지는
-XX:+/-UseTLAB매개 변수로 설정함
- 예컨데 한 스레드가 요청한 객체 A를 위해 메모리 할당 과정에서, 포인터 값 수정전에 다른 스레드가 객체 B용 메모리를 요청할 수 있음
- 메모리 할당 끝났으면 가상 머신은 할당받은 공간을 0으로 초기화(객체 헤더는 제외)
- 스레드 로컬 할당 버퍼 사용한다면 초기화는 TLAB 할당 시 미리 수행
- 자바 코드에서 객체의 인스턴스 필드를 초기화 않고도 사용할 수 있는 이요가 바로 이 단계 덕
- 모든 필드가 자연스럽게 각 데이터 타입에 해당하는 0 값을 담고 있게 되는 것
- 다음 단계로 자바 가상 머신은 ‘각 객체에 필요한 설정’을 해줌
- 예를 들어, 어느 클래스의 인스턴스인지, 클래스의 메타 정보는 어케 찾는지, 이 객체의 해시 코드는 무엇인지(사실 해시 코드는
Object::hashCode())가 처음 호출시 계산함), GC 세대 나이(age)는 얼마인지 등의 정보가 여기 속함- 이런 정보가 각 객체의 객체 헤더에 저장됨
- 객체 헤더를 설정하는 방법은 가상 머신의 현재 구동 모드(편향 락 활성화 여부)등에 따라 달라질 수 있음
- 예를 들어, 어느 클래스의 인스턴스인지, 클래스의 메타 정보는 어케 찾는지, 이 객체의 해시 코드는 무엇인지(사실 해시 코드는
- 그런 다음 이 심벌 참조가 뜻하는 클래스가 로딩, 해석(resolve), 초기화(initialize)되었는지 확인
- 이상의 과정 끝났다면 가상 머신 관점에서는 새로운 객체가 다 만들어진 셈
- 하지만, 자바 프로그램 관점에서는 이제 시작
- 생성자가 아직 시작되지 않았고, 모든 필드는 기본값인 0 인 상태
- 그 외 객체로서 구실하기 위한 여러 자원과 상태 정보 역시 아직 개발자 의도대로 구성 X
- 일반적으로 new 에 이어서 <
init>() 메서드까지 실행되어 객체를 개발자의 의도대로 초기화 해야 비로소 사용 가능한 진짜 객체가 완성됨

2.3.2 객체의 메모리 레이아웃
핫스팟 가상 머신은 객체를 세 부분으로 나눠 힙에 저장. 객체 헤더, 인스턴스 데이터, 길이 맞추기용 정렬 패딩(alignment padding)이다.
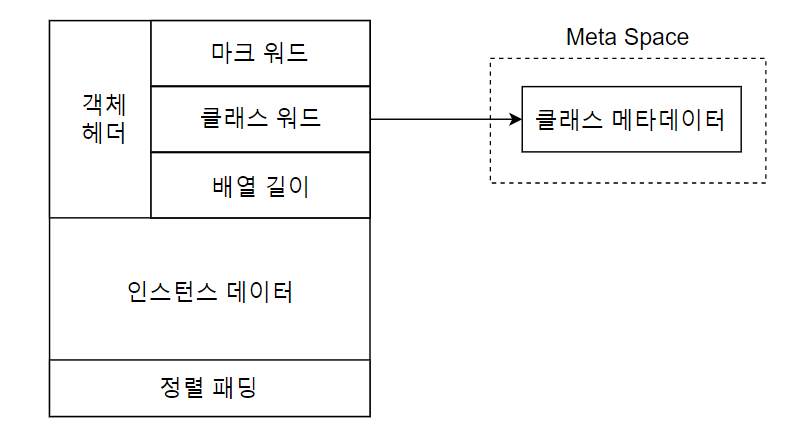
- 객체 헤더
- 마크 워드
- 객체 자체의 런타임 데이터(해시 코드, GC 세대 나이, 락 정보 등)
- 클래스 워드(Klass word)(Klass는 JVM이 런타임에 자바 클래스 다루는데 필요한 각 종 정보가 담겨있는 데이터 구조 지칭)
- 클래스 포인터
- 메타스페이스영역 내부의 클래스 메타데이터 가리킴
- 클래스 포인터
- 배열 길이(배열 객체일 경우)
- 마크 워드
- 인스턴스 데이터
- 객체가 실제로 담고 있는 정보(상속 관계, 필드 등)
- 정렬 패딩
- 전체 크기가 8바이트의 정수배가 되도록 자리 확보
객체 헤더
- 핫스팟 가상 머신은 객체 헤더에 두 유형의 정보 담음
- 첫 유형, 객체 자체의 런타임 데이터
- 해시 코드, GC 세대 나이, 락 상태 플래그, 스레드가 점유하고 있는 락들, 편향된 스레드의 아이디, 편향된 시각의 타임 스탬프 등
- 이 부분을 마크 워드라 하며 차지하는 크기는(참조 압축기능 켜지 않으면) 32비트 가상 머신에서는 32비트이고, 64비트 가상 머신에서는 64비트다
- 헤더에는 객체 자체가 정의한 데이터와 관련 없는 정보까지 담아야 해서 한정된 메모리 최대한 효율적으로 사용해야됨
- 추가 내용은 102쪽 참고!
- 둘째 유형, 클래스 워드(klass word)가 옴
- 객체의 클래스 관련 메타데이터를 가리키는 클래스 포인터가 저장
- 이거 통해서 자바 가상 머신은 특정 객체가 어느 클래스의 인스턴스인지 런타임에 알 수 있다
- 모든 가상 머신 구현이 클래스 포인터를 객체 헤더에 저장하지는 않는다
- 달리 말하면, 객체의 메타데이터 정보를 반드시 객체 자체에서 찾아야하는것은 아님. 자세한건 다음 절
- 첫 유형, 객체 자체의 런타임 데이터
- 추가로 자바 배열 경우 배열 길이도 헤더에 저장. 위치는 클래스 워드 다음
- 자바 가상 머신은 객체 헤더의 메타데이터로 부터 자바 객체의 크기를 얻음
- 하지만, 객체 헤더에 저장되는 객체 타입은 배열에 담긴 ‘원소’의 타입
- 따라서, 배열 길이(원소 개수)까지 알아야 배열 객체가 차지하는 메모리 크기를 제대로 계산 가능
인스턴스 데이터
- 인스턴스 데이터는 객체가 실제로 담고 있는 정보
- 프로그램 코드에서 정의한 다양한 타입의 필드 관련 내용
- 부모 클래스 유무
- 부모 클래스에서 정의한 모든 필드
- 이런게 이 부분에 기록
- 이런 정보의 저장 순서는 가상 머신의 할당 전략 매개 변수(
-XX:FieldsAllocationStyle)와 자바 소스 코드에서 필드를 정의한 순서에 따라 달라짐- 핫스팟 가상 머신은 기본적으로
long double, int, short char, byte boolean, 일반 객체 포인터순으로 할당
- 핫스팟 가상 머신은 기본적으로
정렬 패딩
- 이 부분은 존재하지 않을 수 도 있음
- 특별한 의미 없이 자리를 확보하는 역할
- 핫스팟 가상 머신의 자동 메모리 관리 시스템에서 객체의 시작 주소는 반드시 8바이트의 정수배여야 함
- 달리 말하면 모든 객체의 크기가 8바이트의 정수배여야 한다는 뜻
- 헤더는 8바이트 정수배 되도록 잘 설계되어 있으니 인스턴스 데이터가 이를 못 충족 시킬때 패딩으로 채움
2.3.3 객체에 접근하기
- 대다수의 객체는 다른 객체 여러 개를 조합해 만들어짐
- 자바 프로그램은 스택에 있는 참조 데이터를 통해 힙에 들어있는 객체들에 접근해 이를 조작
- <명세>는 참조 타입을 단지 ‘객체를 가리키는 참조’라고만 정의했을뿐! 힙에서 객체의 정확한 위치를 알아내어 접근하는 구체적인 방법은 규정하지 않음
- 따라서, 객체에 접근하는 방식 역시 가상 머신에서 구현하기 나름
- 주로 핸들이나 다이렉트 포인터를 사용해 구현
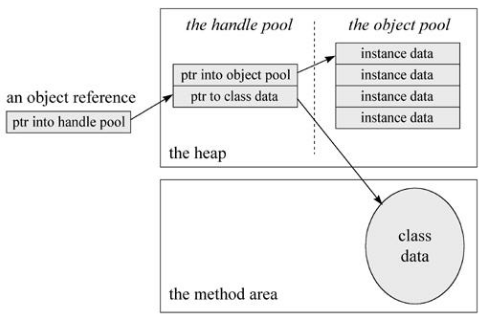
- 주로 핸들이나 다이렉트 포인터를 사용해 구현
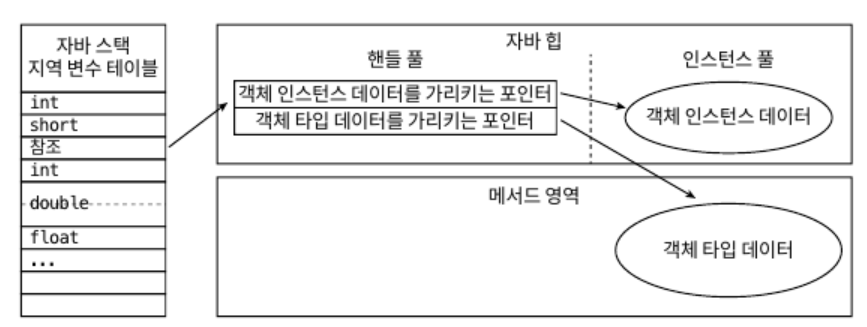
- 핸들 방식
- 자바 힙에 핸들 저장용 풀이 별도로 존재할 것
- 참조에는 객체의 핸들 주소가 저정
- 핸들에는 해당 객체의 인스턴스 데이터, 타입 데이터, 구조 등의 정확한 주소 정보가 저장
- 장점
- 참조에 ‘안정적인’ 핸들의 주소가 저장된다는 것
- 가비지 컬렉션 과정에서 객체가 이동하는 일은 아주 흔함.
- 핸들을 이용하면 이렇게 객체의 위차가 바뀌는 상황에서도 참조 자체는 손댈 필요 없음
- 그 대신, 핸들 내의 인스턴스 데이터 포인터만 변경하면 됨
- 참조에 ‘안정적인’ 핸들의 주소가 저장된다는 것
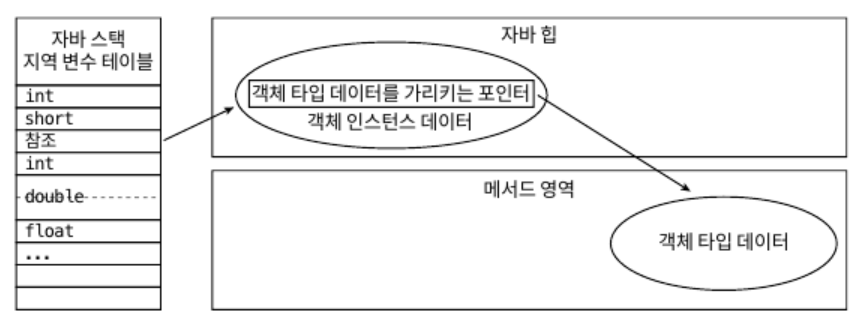
- 다이렉트 포인터 방식
- 자바 힙에 위치한 객체에서 인스턴스 데이터뿐 아니라 타입 데이터에 접근하는 길도 제공해야함
- 스택의 참조에는 객체의 실제 주소가 바로 저장되어 있음
- 장점
- 속도가 빠름. 핸들을 경유하는 오버세이가 없기 때문
- 자바에서는 다른 객체에 접근할 일이 아주 많기에 이 오버헤드도 실행 시간에 영향 크게 줄 수 있음
- 이 책의 주된 논의 대상인 핫스팟은 주로 다이렉트 포인터 방식을 이용
- 시야를 넓혀보면 핸들 역시 다양한 언어나 프레임워크에서 활용하는 보편적 기법